
When you have large data amounts, running the script run can often take quite a lot of time. In such cases, you might consider making an Incremental Load, to save time. I.e. just loading the records that have changed since the last script run.
This used to be quite tricky to achieve, since the Qlik engine is designed to load a fresh copy of the data every time the script is run. However, functionality to support incremental loads was added to the Qlik engine a couple of years ago.
The Merge prefix.
The principle is to define a change set – a set of changed records – and then merge these into a table that already exists in the Qlik data model.
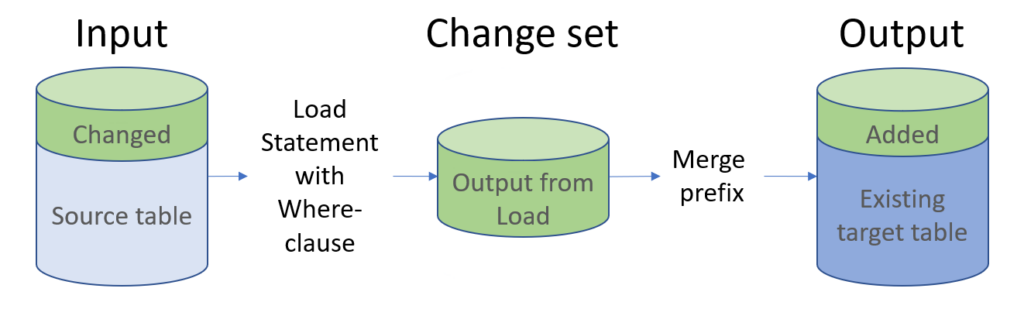
In its simplest form, the corresponding Load statement would look like the following:

“Merge” means that a record can be inserted, updated or deleted in the existing table. Two fields are mandatory: Operation and Key.
Operation
The first field in the Load statement needs to be a text field that defines what should be done: ‘Insert’, ‘Update’, or ‘Delete’. This field will not be loaded into the target table.
Key
There must exist a field that identifies the record that should be changed – a primary key. This should be specified after the “on” clause.
Optionally, you may also want to include a timestamp or sequence number – here the field “ChangeDate”:

ChangeDate
This field needs to be specified as the first parameter to the Merge prefix, i.e. put within the brackets after the prefix itself. It ensures that the operations are performed in the right order and that the last version of the record is the one that is kept. Without this sequence number, the engine uses the load order to determine which record is the last one. The sequence number does not need to be a timestamp – it could be any number that defines the order of the changes.
To summarize: The Merge prefix will look at the fields Operation, Key, and ChangeDate to determine how the target table should be changed:
- The Operation determines the type of change: whether an Insert, Update or Delete should be performed.
- The Key determines which record is affected.
- The ChangeDate determines which record should be kept: Whether the record in the target table should be kept as it is, or the operation in the Merge Load should be performed. The Merge Load needs to have a sequence number higher (i.e. later) than the existing one.
The Merge prefix can be made much more complex, if needed. For example, if you want the Merge statement to be executed at partial reloads only, you can specify this with the “Only” clause. And if you need to specify several fields that together form a primary key, you can do that.
Further, if the change set and the target table have different sets of fields, you need to use the “Concatenate” prefix before the Load keyword.
And finally, if you want to store the last execution time in a variable, so that you can use this in a Where clause in the next script run, you can do this by using a second parameter for the Merge prefix.
In-app merge or QVD layer?
There are two principal approaches to incremental Loads: Either you make the changes directly in a Qlik app, or you use an incremental load to update a QVD layer.
In-app merge
If you choose the in-app approach, you need to use a Partial reload to run the script. In Qlik Sense you can do this by running script from the scheduler with “Partial reload” checked. If you do this, your incremental load should work properly.
A partial reload ensures that the existing tables in the app are not dropped at the beginning of the script run. This is different from a normal script run, that starts by dropping the entire existing data model. Further, a partial reload will not execute other Load statements, unless they are preceded by the prefix “Add”, “Replace” or “Merge”. So, if you have a script with several normal Load statements, and one single “Merge Load”, only the “Merge Load” statement will be executed.
A best practice would be to do something similar to the following:

In a normal reload, only the first Load/Select statement will be executed. In a partial reload, only the second Load/Select statement will be executed.
QVD layer
You can use the above approach also for a QVD layer, but here you also have a second option – one without the partial reload. Then you would create two QVD-generating apps: One that loads all data and one that makes an incremental load.
The script for the incremental load would be similar to the following:
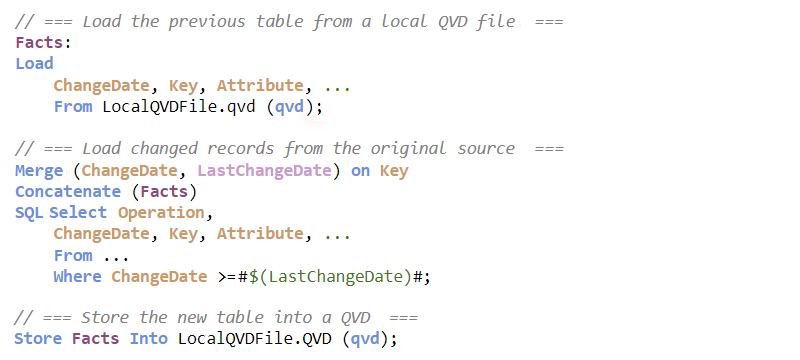
In both approaches, the variable LastChangeDate keeps track of when the last script run was made and makes sure that only new changes are loaded. The Concatenate prefix is, strictly speaking, not necessary. But it could still be good to have it there to ensure that the correct target table is used.
These scripts would both be proper ways of coding an incremental load of one single table. If you have several large tables, you need to repeat this process for each table.
A good practice would be to run a full reload regularly, perhaps once a week or month, and in addition run incremental loads every night.
With this I leave you to investigate the Merge prefix.
Hello, thanks for sharing the knowledge!
Is this approach better than using[NOT] Exists?
Both work fine.
But I think Merge is better since it can handle more use cases: You can update just some of the fields, you can have deletes, etc.
I created some examples with QCDI including transforms and Datamart, and really love the Merge of the Datamart with the ‘In App’ approach. Now we can really have ‘near realtime’ data available in our dashboards because of CDC and in the backend and merge in frontend!! However it is still a pull from App approach I would love to see a push from pipeline approach to the hypercubes of the App…. Is this a strange thought??? 💭
It should be straightforward to do this using the API – i.e. to initiate a script run using an external event. Technically, it would still be a Pull, but it would be perceived as a Push, since it is an external event that triggers it. I’m not an expert on how to to use the APIs, so I cannot give you a code example.
Qlik did have a “Dynamic update” some years ago. This was the possibility to insert data from an external process. However, it complicated things tremendously, and we only had bad experiences from it. So I don’t think the functionality is there anymore.